
This website started as a static site - HTML, CSS, vanilla JavaScript. I migrated it to Astro to create a blog and decided to build it properly: atomic design, reusable components, the whole system. Why? Because I want to dogfood my own AI-assisted design-to-code workflow. If I'm going to teach others how to work with AI, I need to know what actually works.
I'd been pair-programming with Claude to build this - 42 components and counting. But Claude kept making the same mistakes. Using raw HTML when components existed. Duplicating patterns instead of reusing molecules. Picking the wrong component for the job.
The problem wasn't Claude's reasoning. It was context. Claude didn't know when to use each component or why certain patterns existed.
So I built ai-component-metadata. A skill that generates structured documentation for each component - not just props and types, but usage patterns, anti-patterns, when to use this instead of that.
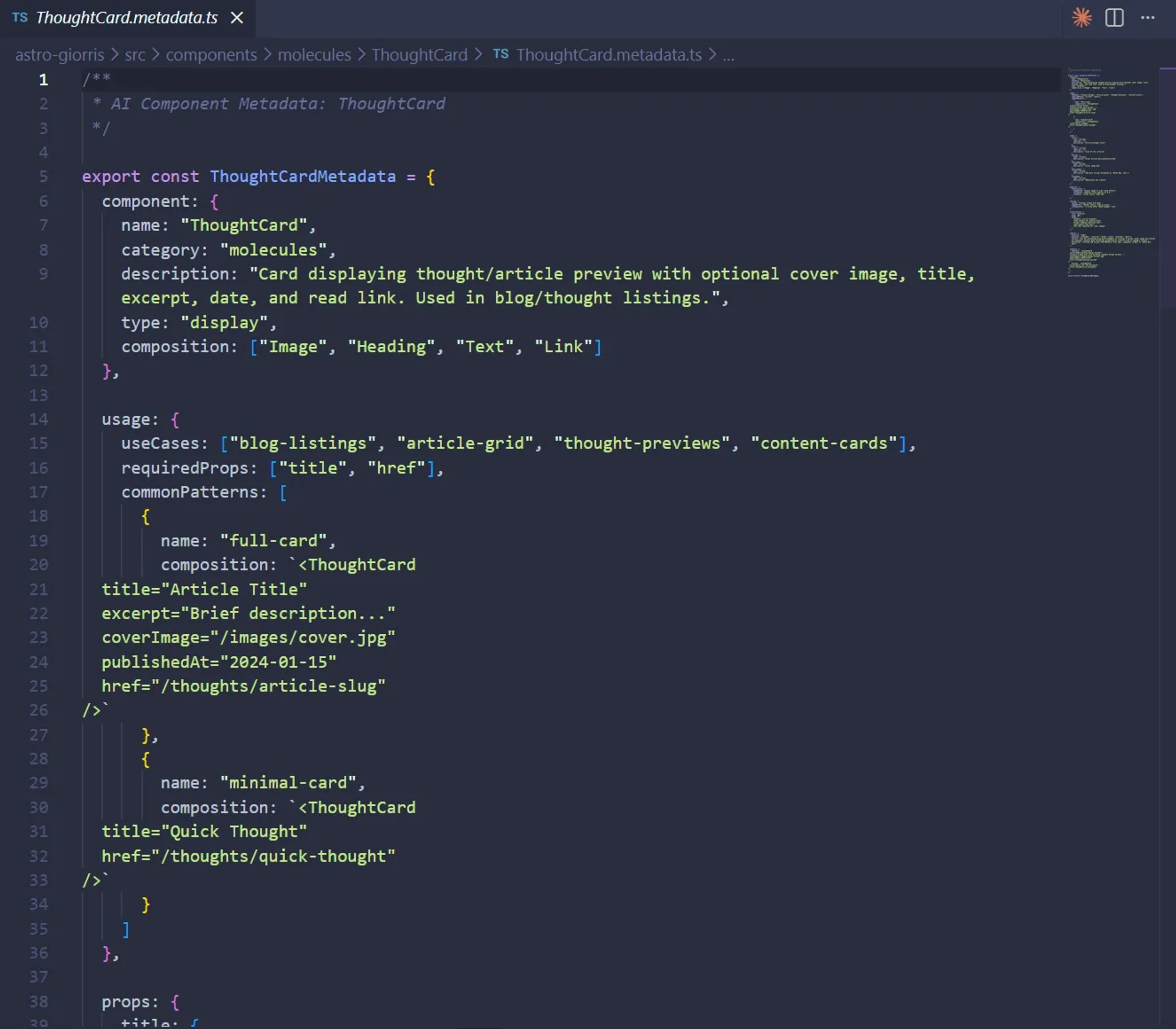
Then I built ai-ds-composer. The reasoning layer. How to think through component selection hierarchically. When to reach for atoms vs molecules. When existing components don't fit and you need something custom.
This worked. Sort of. But every conversation still burned thousands of tokens just loading component context. I'd explain the same relationships over and over.
That's when I found out how Cursor optimizes token usage with codebase indexing. I built codebase-index - a Python script that maps every component relationship, every dependency, every usage pattern into a compact format. Load once per conversation, ~4000 tokens, complete codebase understanding.
I looked at what I'd built: ai-component-metadata (the HOW/WHY), ai-ds-composer (the reasoning), codebase-index (the WHAT/WHERE). Three skills that formed something I hadn't intended to build.
A RAG pipeline. Specifically for design systems.
Dogfooding
This project is 90% claudecoded. I love that term - it captures something specific about how this work actually happens. Pair-programming. Building together.
Dogfooding means using your own product. In this case: using the AI-assisted workflow I'm building to actually build the thing. Finding what breaks, what works, what needs iteration. Real problems surface faster than theoretical ones.
The workflow depends on complexity. Simple components: ask Claude to generate, iterate on styling and behavior in code, validate in the browser. Sometimes I dig into the CSS myself when it needs tweaking.
Complex features start in Figma. I designed the project cards and home sections there, then Claude builds them, I polish the UI in the codebase, test locally, deploy. Sometimes changes come from friends using the actual site - like when we discovered the trackpad scroll was broken in the projects section.
The ThoughtCard incident is a good example.
I'd built a ThoughtCard component for the thoughts index page. Clean, reusable molecule. Then I asked Claude to create a custom layout for the homepage's "Fresh Thoughts" section. Claude made a judgment call: custom layout means inline HTML instead of importing the existing component.
Reasonable interpretation of ambiguous instructions.
I only caught it because the adoption report listed ThoughtCard as "unused." Fast glance, instant wrong-feeling. I know that's used.
So I asked Claude to verify. Go deeper - check metadata, check actual page files. Claude found the duplication. The HTML from ThoughtCard cloned into ThoughtsSection.
The tools catch problems the tools create.
Discovery
I'd just finished a Design Systems bootcamp. One of the recurring themes: adoption metrics are critical, and nobody can get them easily.
Design system teams rely on slow, manual audits. Most don't go into the code - they're tracking adoption through surveys and Figma file inspections. The teams that do have automated tracking use tools like Omlet.
Omlet's pricing: $169/month billed yearly, $199/month monthly. There's a free tier - 4 scans every 30 days with 30-day retention - but I couldn't tell you if it's useful. The barrier for me wasn't just price. It was adding another dependency to test it.
I already had all the data.
My codebase index knew every component relationship. My metadata documented usage patterns. Claude could read structured data and reason about it.
I prompted:
Ten minutes later: a 1,200-line comprehensive analysis. Component utilization rates, unused components, pattern inconsistencies, specific refactoring recommendations. Even with errors, phenomenal starting point.
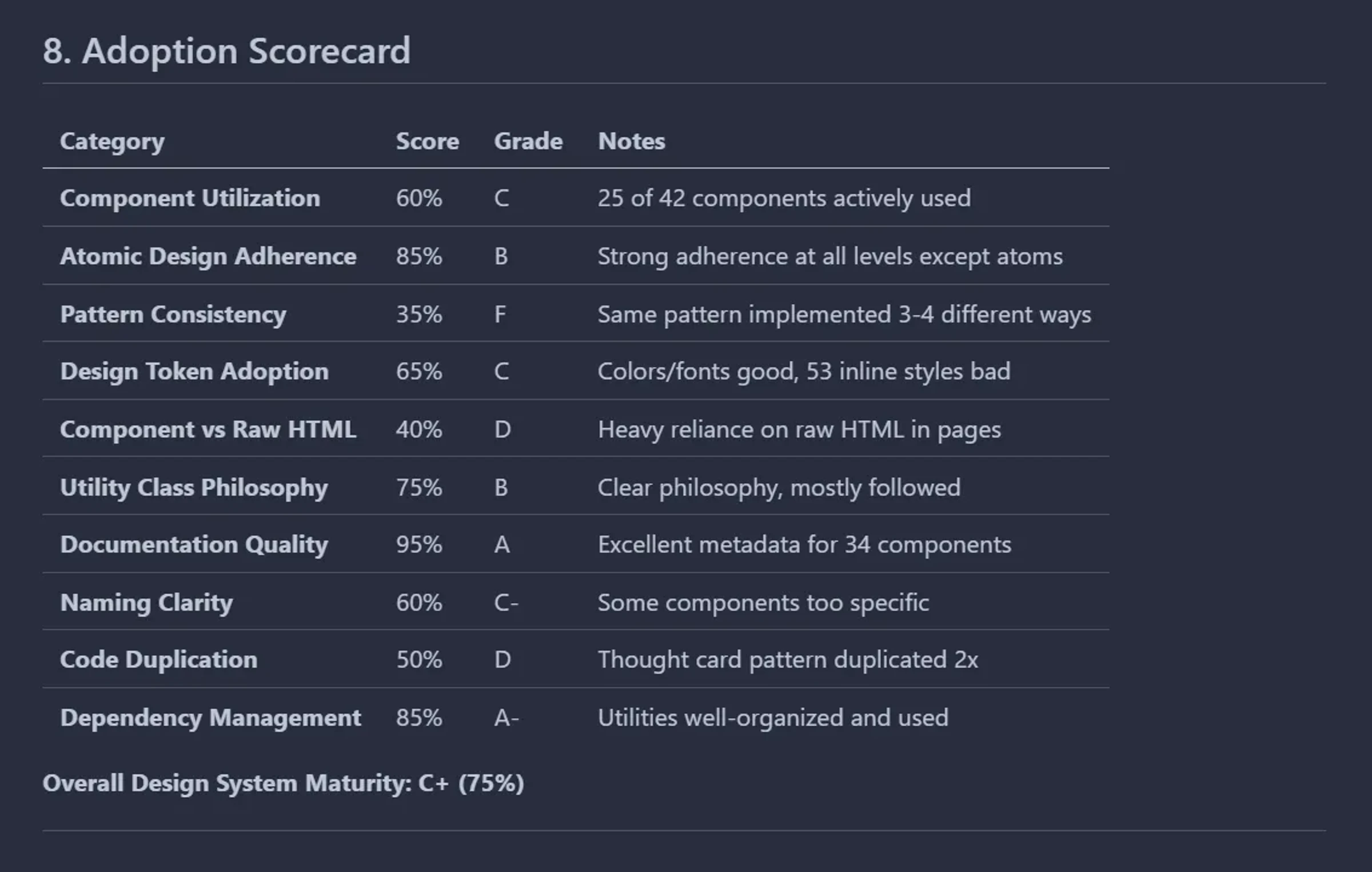
Then I read it. FeaturedSkillsSection marked unused. I knew it rendered on the homepage.
I debug macro to micro with AI. Stay wide enough for Claude to suggest tests, surface patterns I might miss. Then narrow in.
Claude went deeper - cross-referenced metadata against actual page imports. Found the discrepancies. Not just ThoughtCard duplication. The index itself had gaps. Components marked unused that were definitely imported.
The codebase indexer had a bug.
How I fix it
The Python script used file_path.stem as the dictionary key. Filename without extension. Seemed reasonable.
Until multiple files share the same name.
Four pages, silently lost. The homepage data completely erased by subsequent scans.
I asked Claude to create a fix plan. Iterated on the approach. The solution: use full relative paths as keys instead of stems. Guaranteed unique, no collisions.
Changed one line. Regenerated the index.
42 components became 46. Those 4 missing pieces were the overwritten pages, now properly captured.
Ran the adoption report again.
60% component utilization. FeaturedSkillsSection, ThoughtsSection, ProjectsCarouselSection - all showing correct usage. TableOfContents no longer orphaned.
Oh. This actually works.
But only with good data. The whole system depends on context - having it or not. Which brings me to the problem I haven't solved.
The Maintenance Challenge
The system works when the data is fresh.
I update components during development. Add new atoms, refactor molecules, change import paths. The code evolves. But the index and metadata don't update automatically. They sit there, increasingly stale, until I remember to regenerate them.
Not catastrophic debt. Not yet. But someone who doesn't know the codebase well wouldn't notice the drift. They'd trust Claude's suggestions based on outdated context. Use deprecated patterns. Miss newly available components.
The codebase index has auto-update instructions built in. But component metadata doesn't. Both would be better as root-level instructions in CLAUDE.md - the file Claude reads at conversation start.
The real solution is systematic:
CI/CD hooks - Regenerate the index on component changes. Detect when files in /src/components are modified, trigger the Python script, commit the updated index automatically.
Validation layer - Detect when metadata diverges from actual component APIs. If a component's props interface changes but the metadata file doesn't, flag it. Surface the drift before it becomes a problem.
Version stamping - Timestamp the metadata. Let Claude know when data was last generated. "This index is 3 weeks old" changes how much you trust it.
I haven't built these yet. They're next.
What Makes a Design System AI-Ready
AI doesn't need the same documentation humans need.
Humans read Storybook. They browse examples, understand context through visual patterns, internalize conventions over time.
AI needs structured machine-readable context. Not "here's what Button looks like" but "here's when to use Button vs Link, here's the anti-patterns, here's how it composes with other components."
The architecture has three layers:
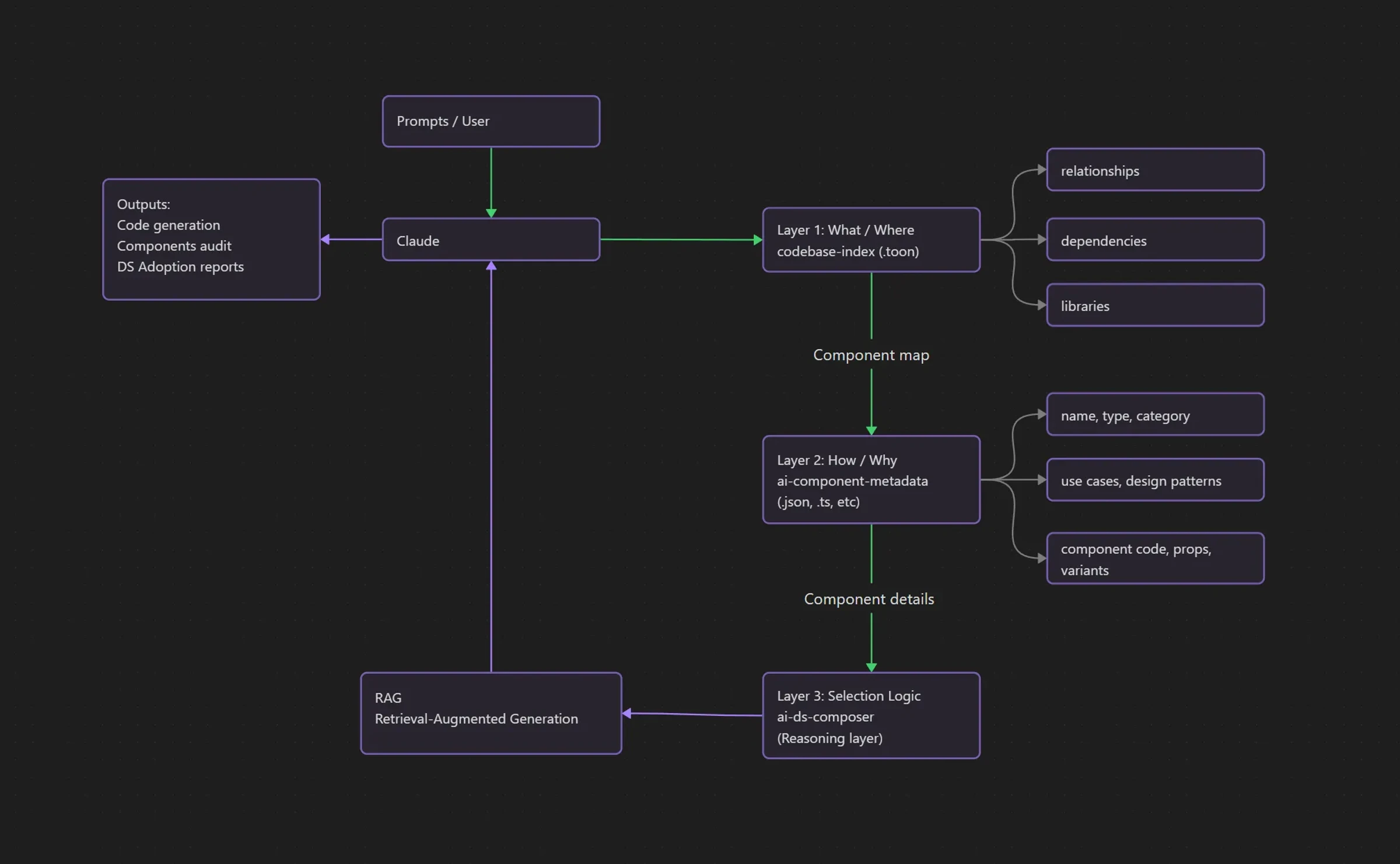
Layer 1: Index (WHAT/WHERE)
The relationship map. What components exist, what uses what, what depends on what. Complete codebase understanding in ~4000 tokens instead of 50,000+. I built this last, which is why the system was imperfect - I was teaching Claude how to use components without giving it a map of what actually existed.
Layer 2: Metadata (HOW/WHY)
Component-level documentation. Usage patterns, design decisions, when to use this instead of that. The reasoning layer humans keep in their heads.
Layer 3: Reasoning (SELECTION LOGIC)
How to think through component choices hierarchically. Start with organisms, work down to molecules, reach for atoms last. When existing components don't fit and you need something custom. The decision framework.
Together, they form a retrieval system. For components.
Your design system becomes queryable. Claude doesn't just know components exist - it knows when to use them, how they relate, why certain patterns matter.
A secondary effect
Adoption reports, architecture analysis, refactoring recommendations. Any question you can ask about component usage, Claude can answer. The data is already there, structured, ready.
What This Actually Solves
AI cost optimization is the next critical trade-off for teams. Every component explanation, every relationship re-described, every context reload costs tokens. Which costs money.
A RAG system for design systems changes the economics. Load once per conversation. Complete context. Minimal cost.
It also changes affordability
Design system adoption tracking usually requires specialized tools or manual effort. Tools like Omlet offer comprehensive tracking and analytics - valuable for teams that can justify the investment and integration effort. But for smaller teams, solo developers, or early-stage projects, there's a gap. Pay for external tooling, build custom analytics infrastructure, or fall back to manual audits.
This approach offers a third path: generate what you need from data that already exists in your codebase. The adoption reports, architecture analysis, refactoring recommendations - they're byproducts of documentation you'd want anyway for AI-assisted development.
The hard part isn't the generation. The hard part is maintenance.
Claude can write reports, suggest refactors, identify patterns. Almost trivial once the data exists. Keeping the data fresh. Building the CI/CD hooks, the validation layers, the version stamping. Making updates automatic instead of manual. That's the work I'm still doing.
This is experimental. Iterative.
Built in public through dogfooding and gap-surfacing. Every issue traces back to human error - my own omissions, incomplete instructions, forgetting to regenerate. More iteration, better systems, clearer processes.
But the foundation works. An AI-Ready Design System isn't just documented for humans. It's structured for machines. Queryable, verifiable, maintainable.